とるにたらない日々 *写真および文章の無断転載はご遠慮ください*
×
[PR]上記の広告は3ヶ月以上新規記事投稿のないブログに表示されています。新しい記事を書く事で広告が消えます。
少数派の環境なので、全然需要なさそうな話題ですが……
【今回使用した道具】
・Mac OSX10.4
・スキャナ
・Adobe CS4(英語版)
> このうちPhotoshopとAcrobat Proを使用
・mi(Mac用テキストエディタ)
【今回使用した道具】
・Mac OSX10.4
・スキャナ
・Adobe CS4(英語版)
> このうちPhotoshopとAcrobat Proを使用
・mi(Mac用テキストエディタ)
「pdfファイルから文字の部分をtxtファイルとして抽出できたら、いろんな使い道がありそうなのに……」
ずっとそんなことを考えていました。
ネットで調べてみると、キーになるのはOCRという、画像上(=pdf)にある文字を認識して読み取ってくれる機能なんですね。
Windows用にはOCRソフトはいろいろ出回っていて、フリーウェアもあるようですが、Mac用はいくら探しても見つからず、どうやらLeopard以後のMacで使える単体ソフト(スキャナーなどにバンドルされていない、という意味で)となると、Readirisのアジア版(199ドル)ぐらいしかないようです。
なので、手持ちの道具でなんとかならないかと、再度トライ。
(以前にもちょっとやってみて、上手くできないので諦めてました)
まずは印刷物をスキャンして画像ファイル(jpg)を作る。
今回はテスト用に、手っ取り早くフラットベッドスキャナで文庫本スキャンしましたが、製本されていないものをドキュメントスキャナなどで取り込めば、もっと綺麗なファイルになります。
画質などはデフォルトおまかせでスキャンしたので、元画像はカラー。
それをPhotoshopで開いて、できるだけクリーンにします。
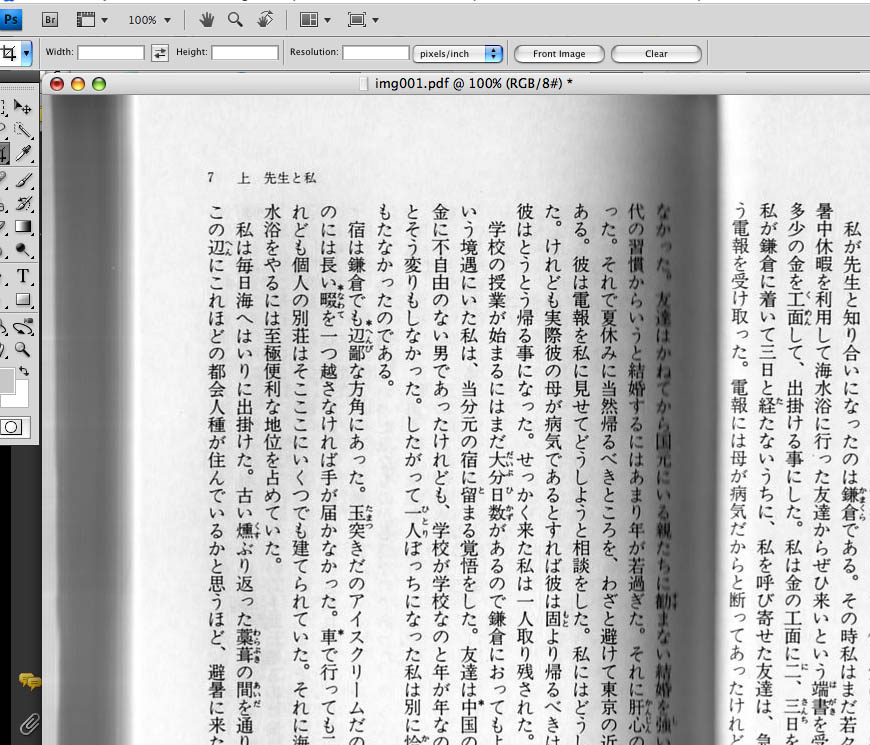
(pdfにexportしてから写真を取り忘れたことに気づいて戻ったので、ファイル名の拡張子はpdfになってますが、スキャナで取り込んだ画像をフォトショで開いた時点では、拡張子はjpgです。まぎらわしくてゴメン)
まずはカラーからモノクロにして、Gray Scaleを選択。
明るさやコントラストなどを調整して、クッキリした画像にする。
*何度も書きますが、今回はテスト用にかなーりテキトーにやっているので、スキャン時の画質選択やフォトショでの修正によっては、もっと綺麗になります。

PhotoshopのFile> Save As> で形式をpdfにして保存し直し、Acrobatで開いたところ。
ノドの部分の陰は、本を裁断しないとやっぱりどうしようもなさそう。
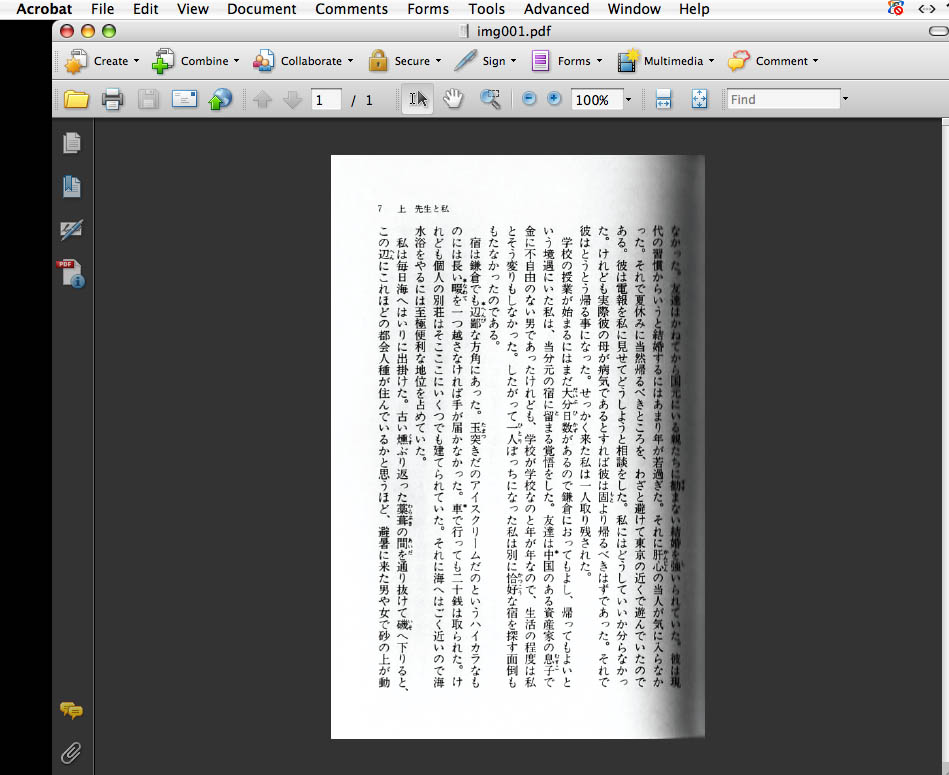
見やすい大きさに表示サイズを変更して………
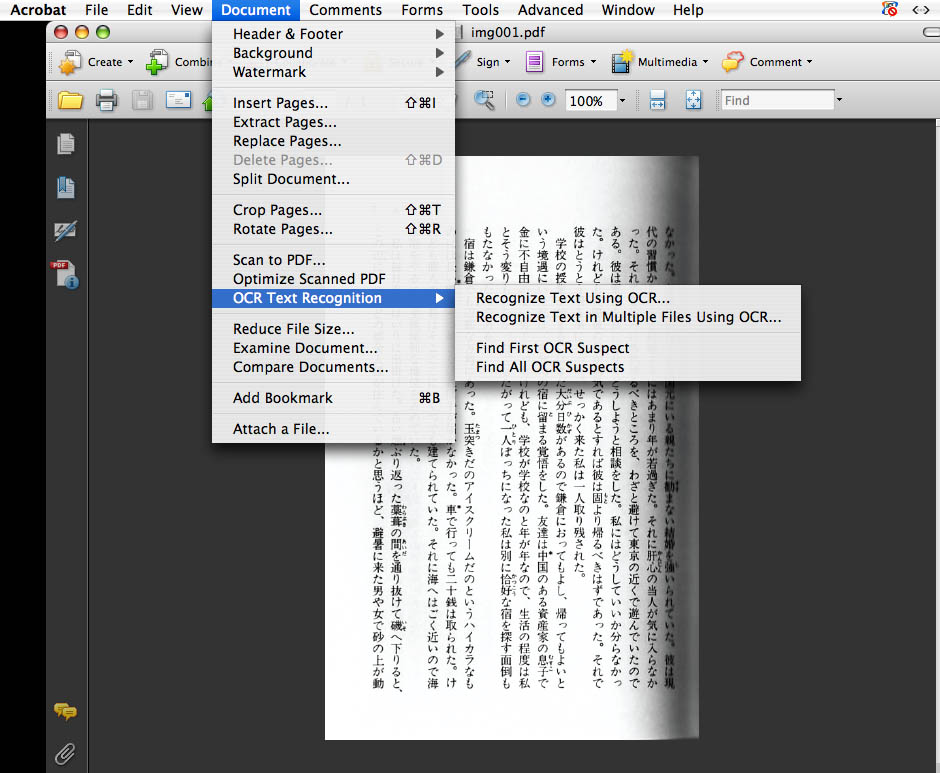
Document> OCR Text Recognition> Recognize Text Using OCR (OCRを使って文字を認識する)
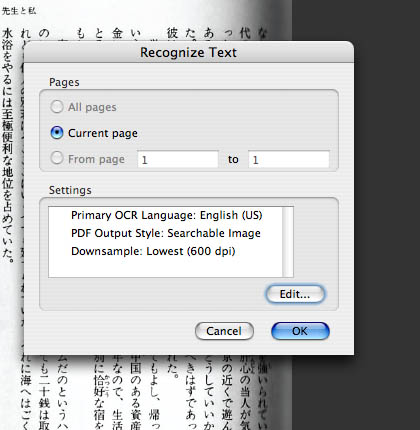
オプション選択が出ます。
今回はテスト用に1ページだけなので、『Current Page』に自動的にチェック入ってますが、裁断→スキャンした自炊pdfなら、『All Pages』もしくはページ範囲を指定するといいです。
で、重要なのが『Setting』のところ。
私のソフトは英語版なので、デフォルトでは『Primary OCR Language』がEnglishになってるんですね。
前回はこれに気づかず、上手くいかなかったようです。
これを『Edit』で『Japanese』に変更→『OK』。
ページ数が多いと結構時間かかりますが、あとは自動で文字を認識してくれます。

認識が終わったら、txtとして書き出したい部分を選択。
上の写真は『コマンド+A』(select all)で選択したもの。
やっぱりノドの部分、文字が綺麗に撮れてないところは無視されました。
もちろんカーソルを使って手動で選択もできますが、やはりノドの部分は選択できませんでした。
選択された状態で『コマンド+C』(コピー)。
なーんかアナログっぽい方法ですが(^^;
テキストエディタを開きます。
これはMacに標準装備のテキストエディタでもいいんですが、それだと改行コードの変更ができないので、私はmiというフリーのテキストエディタを使っています。
これ、いいですよ。
シンプルなテキストエディタなんですが、ウェッブデベロッパー向けなので、htmlやcssを打つのにもすごく便利です。
もちろん今回のようにtxtファイルも作れます。
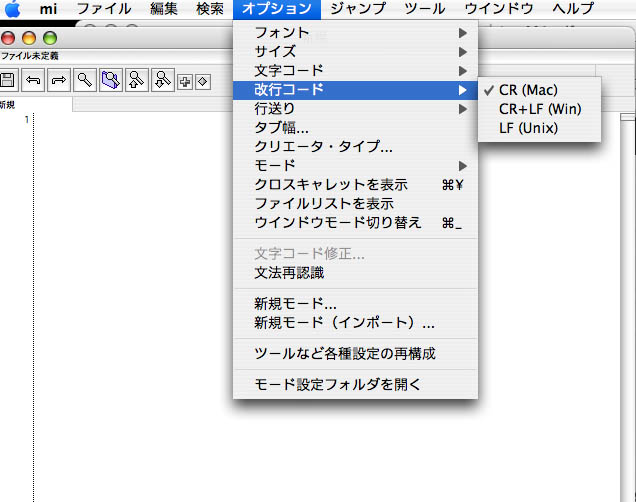
で、オプション> 改行コード で、『CR+LF (Win)』を選択。
これをしておかないと、iPhoneの青空文庫用アプリなど電子書籍ビューワーで開いた時に、改行が反映されません。
つまり、Macの改行じゃダメなんです。
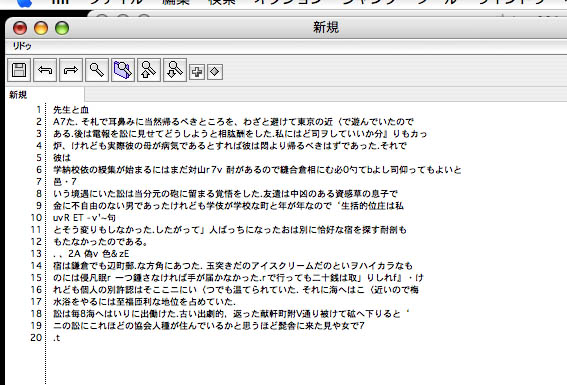
『コマンド+V』(ペースト)しました。
うーん、100%の正確さで文字認識は不可能だとは思ってましたが……
こんな感じです。
もちろん校正が必要ですね。
私としては、これだけでも感動、全然許せる範囲なんですけど。
きっとWindowsユーザーさんは、OCR専用ソフトを使ってることと思います。
もっともっと正確に読み取れるのかな?
どれほどの違いがあるのか興味津々です。
それから何百ページもある場合はフォトショでの修正が大変すぎるので、スキャンする時点でグレイスケールの高画質を選択しておくといいですよ。
で、今回私が紹介したフォトショの工程は完全にスキップしてよいかと。
画質とスピードとファイルの大きさの兼ね合いを考えるとどのくらいがいいのか、どなたかご存知でしたら教えてください〜。
またいろいろ試してみますね(^^)

応援クリックお願いします^^
ずっとそんなことを考えていました。
ネットで調べてみると、キーになるのはOCRという、画像上(=pdf)にある文字を認識して読み取ってくれる機能なんですね。
Windows用にはOCRソフトはいろいろ出回っていて、フリーウェアもあるようですが、Mac用はいくら探しても見つからず、どうやらLeopard以後のMacで使える単体ソフト(スキャナーなどにバンドルされていない、という意味で)となると、Readirisのアジア版(199ドル)ぐらいしかないようです。
なので、手持ちの道具でなんとかならないかと、再度トライ。
(以前にもちょっとやってみて、上手くできないので諦めてました)
まずは印刷物をスキャンして画像ファイル(jpg)を作る。
今回はテスト用に、手っ取り早くフラットベッドスキャナで文庫本スキャンしましたが、製本されていないものをドキュメントスキャナなどで取り込めば、もっと綺麗なファイルになります。
画質などはデフォルトおまかせでスキャンしたので、元画像はカラー。
それをPhotoshopで開いて、できるだけクリーンにします。
(pdfにexportしてから写真を取り忘れたことに気づいて戻ったので、ファイル名の拡張子はpdfになってますが、スキャナで取り込んだ画像をフォトショで開いた時点では、拡張子はjpgです。まぎらわしくてゴメン)
まずはカラーからモノクロにして、Gray Scaleを選択。
明るさやコントラストなどを調整して、クッキリした画像にする。
*何度も書きますが、今回はテスト用にかなーりテキトーにやっているので、スキャン時の画質選択やフォトショでの修正によっては、もっと綺麗になります。
PhotoshopのFile> Save As> で形式をpdfにして保存し直し、Acrobatで開いたところ。
ノドの部分の陰は、本を裁断しないとやっぱりどうしようもなさそう。
見やすい大きさに表示サイズを変更して………
Document> OCR Text Recognition> Recognize Text Using OCR (OCRを使って文字を認識する)
オプション選択が出ます。
今回はテスト用に1ページだけなので、『Current Page』に自動的にチェック入ってますが、裁断→スキャンした自炊pdfなら、『All Pages』もしくはページ範囲を指定するといいです。
で、重要なのが『Setting』のところ。
私のソフトは英語版なので、デフォルトでは『Primary OCR Language』がEnglishになってるんですね。
前回はこれに気づかず、上手くいかなかったようです。
これを『Edit』で『Japanese』に変更→『OK』。
ページ数が多いと結構時間かかりますが、あとは自動で文字を認識してくれます。
認識が終わったら、txtとして書き出したい部分を選択。
上の写真は『コマンド+A』(select all)で選択したもの。
やっぱりノドの部分、文字が綺麗に撮れてないところは無視されました。
もちろんカーソルを使って手動で選択もできますが、やはりノドの部分は選択できませんでした。
選択された状態で『コマンド+C』(コピー)。
なーんかアナログっぽい方法ですが(^^;
テキストエディタを開きます。
これはMacに標準装備のテキストエディタでもいいんですが、それだと改行コードの変更ができないので、私はmiというフリーのテキストエディタを使っています。
これ、いいですよ。
シンプルなテキストエディタなんですが、ウェッブデベロッパー向けなので、htmlやcssを打つのにもすごく便利です。
もちろん今回のようにtxtファイルも作れます。
で、オプション> 改行コード で、『CR+LF (Win)』を選択。
これをしておかないと、iPhoneの青空文庫用アプリなど電子書籍ビューワーで開いた時に、改行が反映されません。
つまり、Macの改行じゃダメなんです。
『コマンド+V』(ペースト)しました。
うーん、100%の正確さで文字認識は不可能だとは思ってましたが……
こんな感じです。
もちろん校正が必要ですね。
私としては、これだけでも感動、全然許せる範囲なんですけど。
きっとWindowsユーザーさんは、OCR専用ソフトを使ってることと思います。
もっともっと正確に読み取れるのかな?
どれほどの違いがあるのか興味津々です。
それから何百ページもある場合はフォトショでの修正が大変すぎるので、スキャンする時点でグレイスケールの高画質を選択しておくといいですよ。
で、今回私が紹介したフォトショの工程は完全にスキップしてよいかと。
画質とスピードとファイルの大きさの兼ね合いを考えるとどのくらいがいいのか、どなたかご存知でしたら教えてください〜。
またいろいろ試してみますね(^^)
応援クリックお願いします^^
PR
コメントする
categories
archive
profile

my friends


